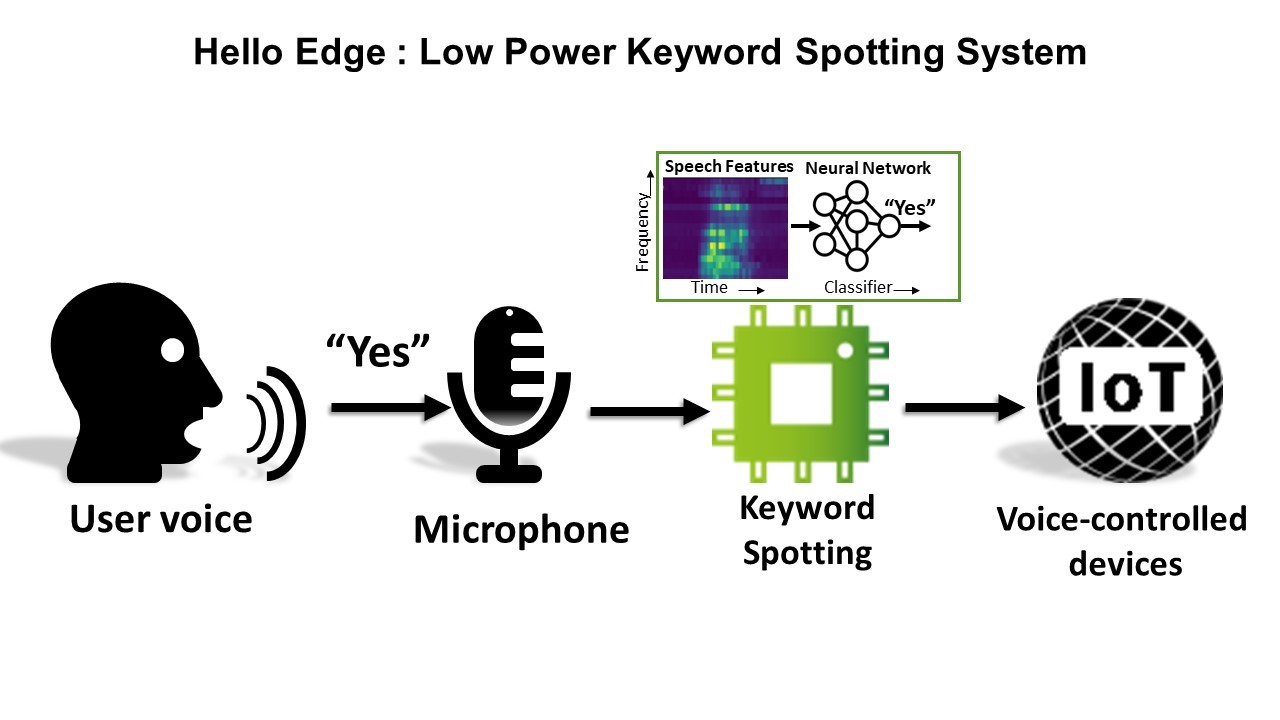
GRENOBLE, France – Feb. 21, 2024 – CEA-Leti has developed a keyword-spotting system that dramatically improves accuracy in always-on, voice-activated Edge-AI systems and that consumes less power in a far smaller silicon footprint than current technology.
Presented in a paper at ISSCC 2024 in San Francisco, the new architecture uses time-domain signal processing on oscillators locked by injection and is suitable for devices running on energy harvesters, which supply power below 0.5V. The paper, “0.4V 988nW Time-Domain Audio Feature Extraction for Keyword Spotting Using Injection-Locked Oscillators", reports accurate speech recognition at power consumption below one microwatt.
It describes the first injection-locked, oscillator-based time-domain audio feature extraction (TD-FEx) demonstrating keyword spotting operating down to 0.4V, while achieving 91 percent accuracy on 10 words. TD-FEx information is not coded as a voltage but as a time delay of two clocks' signals. In addition to being well suited for advanced nodes, its advantages are digital-like implementation with low-supply voltage and better noise immunity than current systems. CEA-Leti's system demonstrated accurate speech recognition with power consumption below 1 µW.
Some analog-based audio feature extraction (FEx) units using multi-channel Gm-C bandpass filters can supply 10 times the power efficiency of digital FEx units in a comparable silicon area. “However, analog FEx circuits have not demonstrated KWS with more than four keywords," the paper reports. “They also suffer from a large footprint, challenging technology migration and limited dynamic range at low supply voltage, while speech signals have inherently a high dynamic range."
Our system's silicon area of 0.15mm2 is at least 3.5 times smaller than prior art on the same process node of 65nm," said Ali Mostafa, lead author of the paper. “With a power of 988nW, our system is nine times more power-and-area efficient than ring-oscillator-based TD-FEx.
Applications beyond speech recognition for this system include predictive maintenance and health monitoring that require on-line frequency decomposition of the sensor data.